LLaMAモデル GGMLフォーマット(llama.cpp)をRustフレームワーク Leptosを用いて M1MacMiniでサクッと動かす。
2024.01.11
この記事は最終更新日から1年以上が経過しています。

どもです。
タイトル悩みました。
今回は、Rustのフルスタックフレームワーク 「Leptos」用いて、Meta社が開発した大規模言語モデル(LLM)LLaMAのGGMLフォーマット(llama.cpp)を、M1 MacMiniのローカル環境で動かそうといったところになります。(長い)
一から作成するわけではなく、既に作成された方がGitHubにアップされていますのでそちらを扱っていこうといった感じになります。
そのレポジトリはこちらになります。
なので、比較的サクッと動かせるかなと思います。
準備
まずは、準備としてRustのtoolをインストールしていきます。
rustup toolchain install nightly rustup target add wasm32-unknown-unknown cargo install trunk cargo-leptos
完了しましたら、レポジトリをgit clone。
git clone git@github.com:MoonKraken/rusty_llama.git
こちらのソースですが、CSSにTailwindCSSを使用していますので、TailwindCSSのnodeモジュールをインストールします。
npm install -D tailwindcss
cssを出力しないといけないので、プロジェクトのルートにて以下のコマンドでcssを出力します。
npx tailwindcss -i ./input.css -o ./style/output.css --watch
モデルの準備
使用するモデル、LLaMAのGGMLフォーマット(llama.cpp)をダウンロードします。
今回は、Wizard-Vicuna-7B-Uncensored.ggmlv3.q4_K_S.binを使用しました。
こちらから使用するモデルをダウンロードします。
対象のモデルをダウンロード
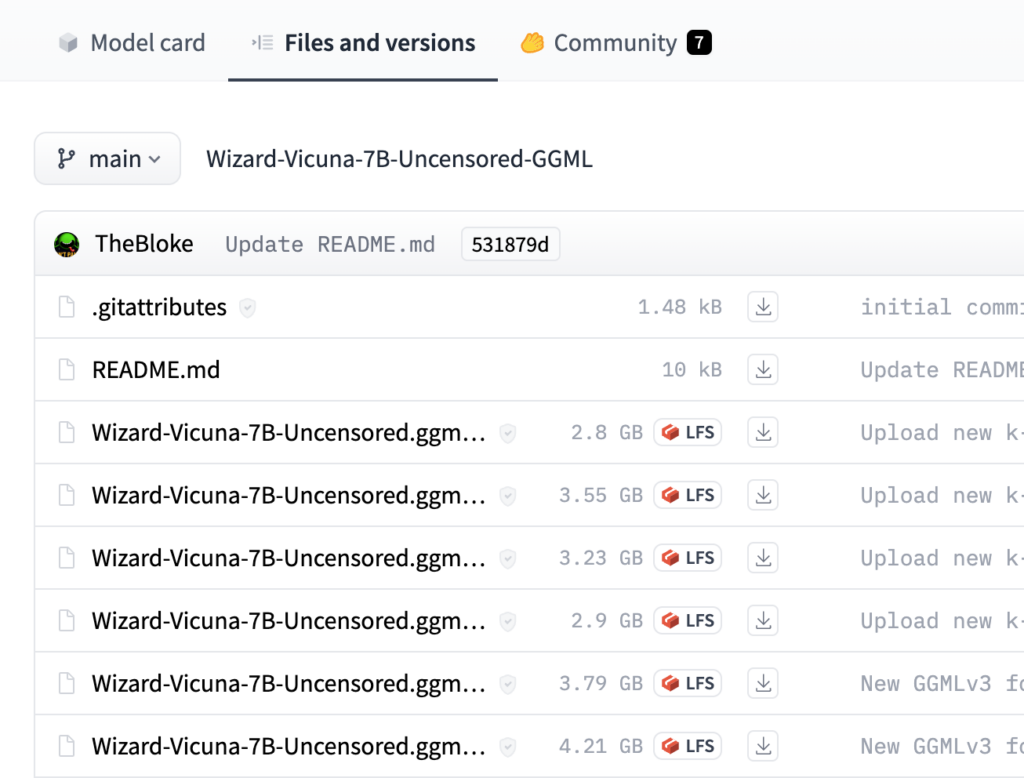
Leptos側で、モデルのimportが必要となるので「.env」ファイルのMODEL_PATHをダウンロードしたモデルのパスに変更します。該当ファイルはこちら。
それでは準備が完了しましたので起動。
起動
それでは起動。
cargo leptos watch
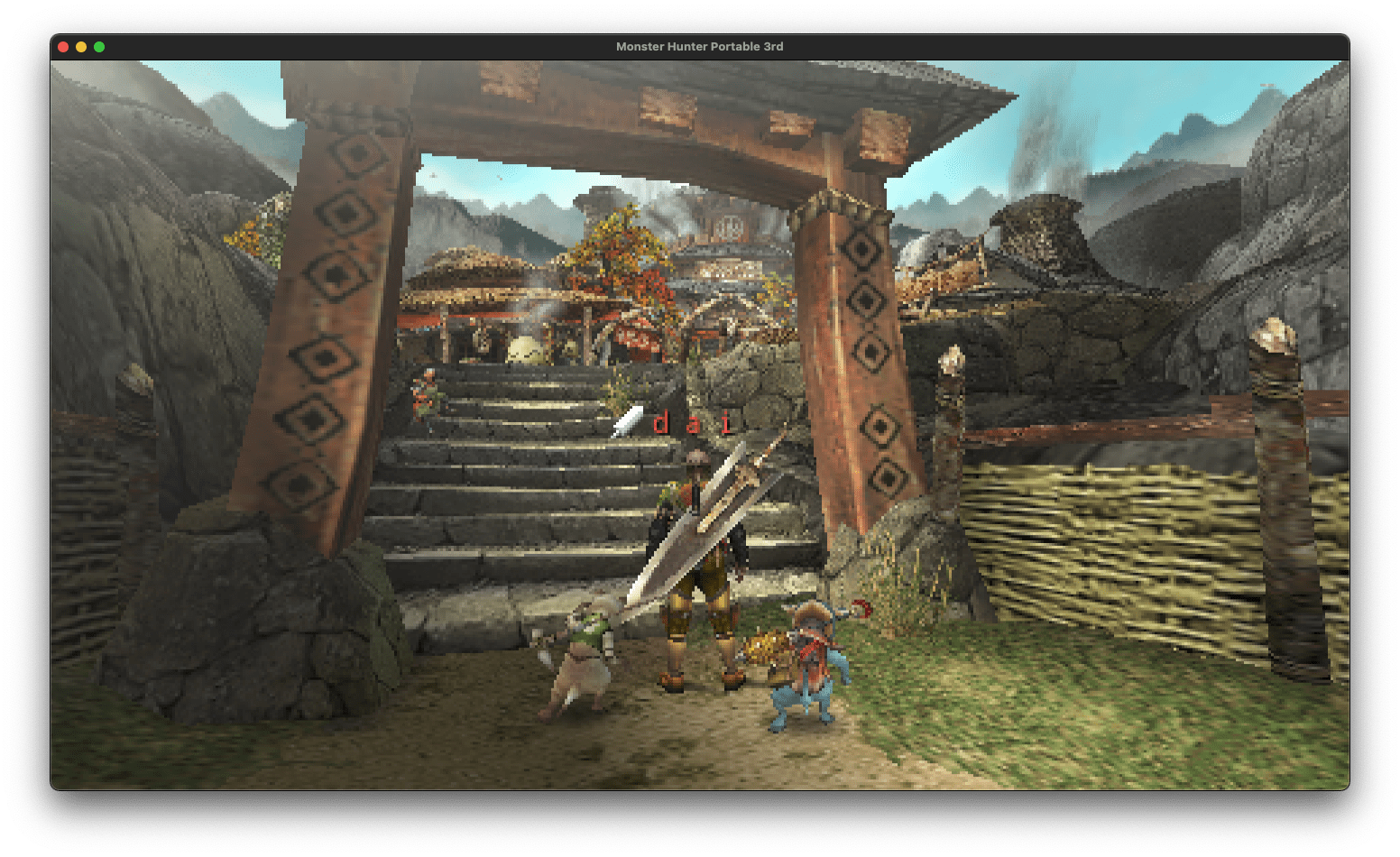
http://localhost:3000/ を開いて、プロンプト入力画面が表示したら優勝です。
実行した環境は、M1 MacMiniでしたが、結構サクサクに返信も返ってきて良い感じでした。
日本語もいけそうな様子だったので日本語解説を求めたのですが、当たり前ですが精度は良くない様子でした。
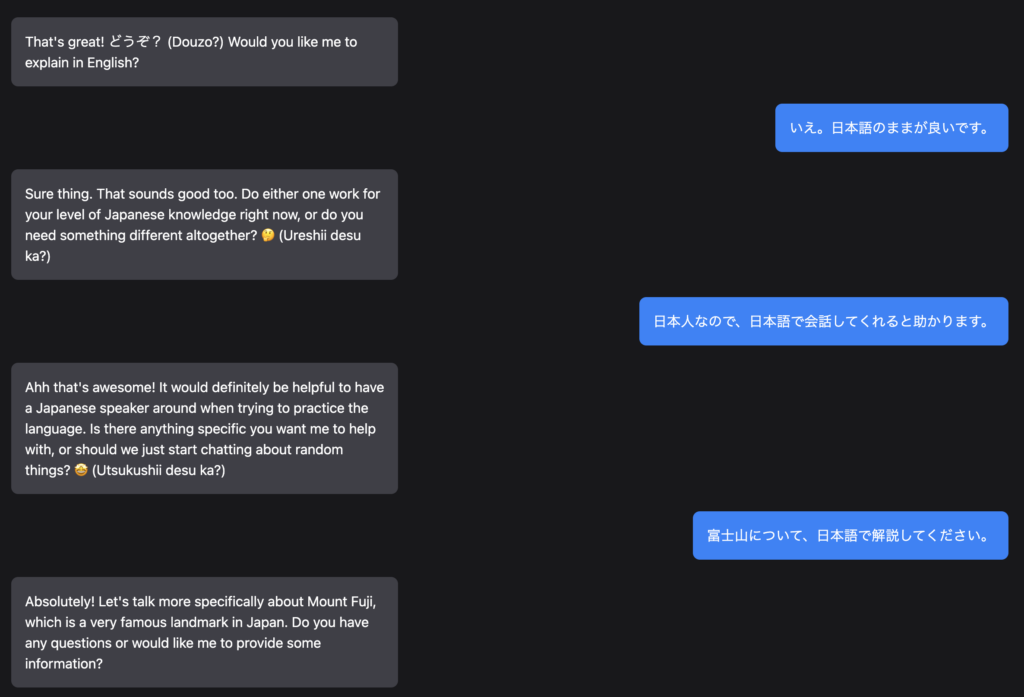
実装方法と共に、コードの解説もyoutubeに上がってはいますが、GitHubにあがっているソースとかなり異なりそのまま作成しても起動しません。解説として見て頂く形が良いかと思います。
比較的サクッと、ローカルPCでLLaMAのGGMLフォーマット(llama.cpp)をLeptosで扱うことができたかと思います。
実は、「Leptos」を扱おうと調べていたらこちらを発見したので試した次第でした。
おかげで、「Leptos」自身の仕様やAPIなどの把握がまだちゃんとできていないです。
これからLeptos扱っていこうと思います。
ではでは。
またまたぁ。